
13.03.2024
1
Like
59
Views
MACHİNE LEARNİNG VE VERİ BİLİMİNDE MODEL EĞİTİMİ
NEDİR BU VERİ BİLİMİ ?
Hepinize merhaba değerli okuyucular,bugün sizlere son zamanlarda adını sıklıkla duyduğumuz her yerde geçen ‘veri ,veri bilimi,bu veri bilimi ne ulan?,bende veri bilimci olacağım beee’ diye herkesin ağzında yer edinmeye başlamış olan veri bilimini inceleyecek olacağımız serimizin ilk yazısına başlayarak veri biliminin temelleri ve bilinmesi gerekenleri sizlere anlatacağım.
BAŞLAYALIM :)

Veri bilimi en temel tabiriyle verilerin anlamlı sonuçlar halinde bilgiye dönüştürülmesi ve bir amaç uğruna sonuçlar üretilmek üzere verilerin bir araya getirilmesi denilebilir
Veri toplama,veri ön işleme,veri görselleştirme,veri modelleme basamaklarından oluşan veri bilimi dalı büyüyen dataların kontrolü ve anlamlı bilgilerin elde edilmesi için oldukça önemlidir.
Bu bağlamda veri bilimi alanında makine öğrenimi, çok büyük miktarda veriyi analiz etmek ve bu verilerden anlamlı bilgi ve öngörüler elde etmek için önemli bir araçtır
MAKİNA ÖĞRENMESİ Mİ O DA NE??

Makine öğrenimi (Machine Learning), bilgisayar sistemlerinin belirli bir görevi yapmak için deneyim veya veriye dayalı olarak öğrenme yeteneğini ifade eder. Bu öğrenme süreci, geleneksel olarak açıkça programlanmış talimatlar yerine veriye dayalı algoritmaların kullanılmasını içerir.
Yani bu durum ise bize aslında machine learning’in ‘Allah tarafından yer yüzüne indirilmiş inanılmaz araçlar ’ değilde sadece geleneksel programlamanın her tahmine göre kod yazma ve detayları koda dökme mantığ yerine makineyi bazı verilerle eğiterek daha sonraki aşamlarda makinenin kendi kendini eğitip komutsuz şekilde x in f(x) değeri şeklinde outputlar üretebilmesini sağlayan değişik bir programlama paradigması denebilir.
Makine öğrenimi genellikle 3 kategoride incelenir :
- Denetimli Öğrenme (Supervised Learning):
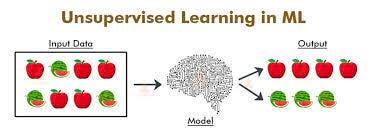
Denetimli öğrenme, girdi verileri ile bu verilere karşılık gelen çıktıları içeren bir eğitim veri kümesi üzerinde çalışır. Amacı, yeni girdi verileri üzerinde doğru çıktıları tahmin etmek için bir model oluşturmaktır. Bu kategori, sınıflandırma (classification) ve regresyon (regression) gibi alt kategorilere ayrılabilir.
Sınıflandırma, bir veri örneğini belirli kategorilere veya sınıflara atama görevini ifade ederken, regresyon ise bir veri örneği ile ilişkili sürekli bir çıktı değeri tahmin etme görevini ifade eder
Yani aslında denetimli öğrenme bizim önceden belirli labellar vererek
makineyi eğitip bu eğitime göre daha sonra sonuçlar üretmesini sağlar
Örneğin makinenin elma ve armudu ayırt etmesi için daha öncede
birkaç çilek ve elma resmi verip daha sonra bu eğitime göre
makineye verilecek olan inputların elma veya armut olup olmaması tahmini bir denetimli öğrenme sonucu elde edilmiştir
2. Denetimsiz Öğrenme (Unsupervised Learning):
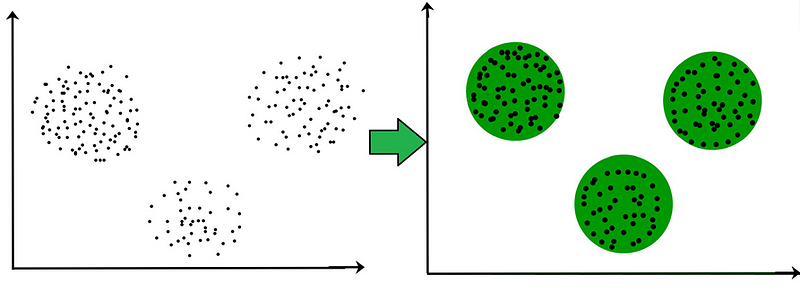
Denetimsiz öğrenme, etiketlenmemiş veri kümesi üzerinde çalışır, yani herhangi bir çıktı etiketi yoktur. Bu tür öğrenme genellikle veri kümesindeki yapıyı veya desenleri bulmak için kullanılır. Yani biz makineye belirli bir veri seti veriyoruz ve makinede bize bunları kendi yorumlamasına göre şekillendiriyor denilebilir Örneğin makineye verilen memeli hayvanlar setinde modelimizin kendi kendine uçabilen memeliler ve uçamayan memeliler olmak üzere bir gruplama yapması buna örnektir.
Kümelenme (clustering) ve boyut azaltma (dimensionality reduction) bu kategoriye örnek verilebilir.
3) Pekiştirmeli Öğrenme (Reinforcement Learning):
Pekiştirmeli öğrenme, bir ajanın belirli bir ortamda belirli bir hedefi maksimize etmek için deneyim yoluyla öğrenmesini içerir. Bu öğrenme, bir ajanın aldığı eylemlerin sonuçlarına göre ödüller veya cezalar almasını içerir.

Buda bize makine öğrenmesinin veri biliminde oldukça önemli olduğunu ve verilerden anlamlı birer bütünler çıkarmak istiyorsak modelimizi iyi eğitmemiz gerektiğini göstermektedir
Peki modellerin tahmin yaparkenki amacı nedir ?
Şu unutulmamalıdır ki modelleri ana amacı girdilerimizi en az hata verecek şekilde çıktılara dönüştüren fonksiyonu bulmaktır.
Bunun içinse model eğitilirken’ train-validation-test’ yaklaşımı ile modeller eğitilmeli ve modelin overfitting(ezbere dayalı yaklaşım) yapılması engellenmelidir
train-validation-test yaklaşımı:

Modelimi sadece train üzerinde eğitiyorum validation ile modelin hyperparameter (hiper parametre)’lerini ayarlıyorum. Ama bu hyperparameter güncellemesini validation üzerinde iyi yapmasına göre yaptığım için modelim dolaylı olarak da olsa validation setine overfit etmeye başlıyor, bu yüzden dolaylı olarak da hiç görmediği verilere ihtiyacım var test etmek için
Çünkü asıl amaç bizim verdiğimiz verilerde kusursuz çalışması değil bu verilerden anlamlı ve analizli öğrenmeler elde edinip daha önce görmediği verilere de en haz hatayla yaklaştığı gibi bizim eğitim verilerimize de hata ile yaklaşabilmeli yani amacı ulan ‘en az hata üreten fonksiyonu üretebilmeli mantığına uygun olmalıdır’
Tabi veri seti modeli oluşturulurken ve makinemiz eğitilirken verilerin ve modelin iyi bir sonuç olması için eğitilecek verinin yanlılık taşımaması yani bias olmaması için (google translate’in veri eğitirken güçlü veya doktor gibi kelimelere eril (he(erkek))güzel veya hemşire gibi kelimelere ise dişil (she(kadın)) şeklinde çeviri yapması gibi) çalışmalarımızda çeşitliliği arttırmalı farklı veriler kullanmalı farklı veriler yani başkasının verilerini kullanırken de o verilerin bias içermemesine emin olmalıyız
Yazımı okuduğunuz için hepinize teşekkür eder ; Keyifli çalışmalar dilerim :))
Comments
You need to log in to be able to comment!
Emir Yılmaz
Merhaba ben inönü üniversitesi yazılım mühendisliği 2.sınıf öğrenciyim amacım liseden beri merak saldığım yazılım sektöründe kendimi geliştirmek ve her gün bu alanda yeni bilgiler öğrenip severek okuduğum ve ileriediğim bölümde iyi konumlara gelmek
Location
İstanbul, TR
Education
Yazılım mühendisliği - İnönü üniversitesi